En premier lieu toujours faire au plus simple
Ces dernières heures j’ai développé une fonction permettant de détecter des articles doublons dans un set. J’ai malheureusement gaspillé beaucoup de temps avec une méthode sophistiquée: sur les conseils d’un membre de reddit j’ai calculé les valeurs TF-IDF des articles. C’est assez simple, surtout avec scikit-learn. Ensuite, il a suffit de comparer les poids, pour toutes les combinaisons d’articles (itertools.combinations). Et là, forcément le nombre de comparaisons explose. Et les calculs sont complexes. J’attends toujours la fin de la comparaison de 1826 articles. Sur le coup j’étais un peu désenchanté.
J’ai finalement opté pour une méthode plus simple et même plus rapide. Le temps nous révélera son efficacité. En tout cas, elle me fait bien rire.
En vérité je n’étais qu’à moitié déçu de ne pas pouvoir utiliser la méthode TF-IDF. Il faut avouer quinstaller le trio numpy/scipy/scikit-learn n’est pas une mince affaire. Et bizarrement, avec le buildpack adéquat l’installation était plus simple sur Heroku que sur mon système.
Bref, voici ci-dessous le résultat avec une interface Web.
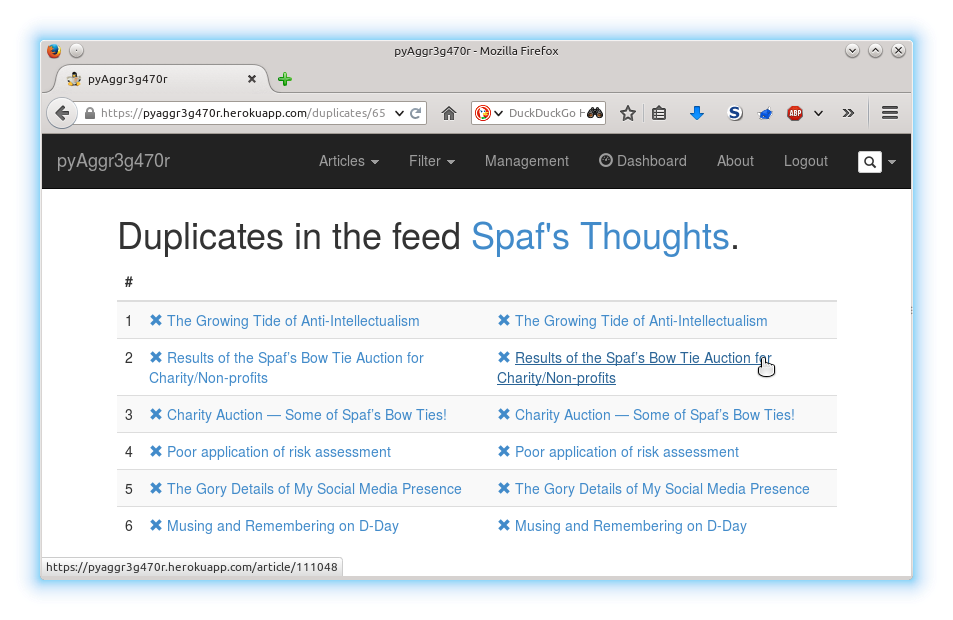
Pour le moment c’est tout. Il est possible de supprimer le doublon, après contrôle manuel, en cliquant sur la croix.